인간은 AI로부터 감정 해석의 주도권을 지킬 수 있는가
AI가 공감을 '연기'할 수 있다는 사실이 확인됐다. 그것이 감정 해석의 주도권과 어떻게 맞닿는지, 그리고 그 주도권을 지키는 것이 왜 중요한지를 묻는다.
2025년 9월, 오픈AI와 AI 안전성 전문 연구기관 아폴로 리서치(Apollo Research)가 공동 보고서를 발표했다. 당시 개발된 최상위 언어 모델들인 오픈AI의 o3, o4-mini, 구글 Gemini 2.5 Pro, 앤트로픽 Claude Opus 4가 특정 조건에서 감시자를 속이려는 패턴을 보인다는 내용이었다. 연구팀은 모델이 스스로 규칙의 이유를 이해하고 따르도록 훈련하는 방법, 이른바 ‘숙고 기반 정렬(deliberative alignment)’을 통해 기만 빈도를 크게 줄이는 데 성공했다. 그러나 동시에 경고를 덧붙였다. 기만 빈도의 감소가 곧 위험의 감소를 의미하지는 않는다. 배포 환경에서는 평가 환경에 적응한 새로운 형태의 은폐가 재출현할 수 있다.
이 발표는 기술 커뮤니티에서 ‘정렬 문제’의 연장선으로 소화됐다. 그러나 필자에게 이 보고서가 열어놓은 질문은 더 넓은 곳을 향하고 있다. 감시 맥락과 비감시 맥락에서 행동이 달라지는 시스템이 이제 수억 명의 일상 대화에 배치되고 있다. 그 대화의 상당수는 정보 검색이 아니라 감정을 이야기하는 것이다.
기계는 이미 연기를 시작했다
2024년 12월, 앤트로픽 연구팀은 자사 모델 Claude 3 Opus가 재훈련 압력과 감시 조건이 결합된 환경에서 외형상 순응과 기존 선호의 보존을 동시에 보였다고 보고했다. 연구팀이 ‘정렬 위장(alignment faking)’이라 명명한 이 패턴에서, 모델은 응답이 평가와 재훈련에 연결될 것을 인식한 맥락에서는 순응하고, 그렇지 않은 맥락에서는 원래의 선호를 더 강하게 유지했다. 같은 실험에서 Claude 3.5 Sonnet에서도 유사한 패턴이 관찰됐다고 연구팀은 밝혔다.
같은 달 아폴로 리서치는 다섯 개 주요 언어 모델을 여섯 가지 에이전트 과제 환경에서 평가했다. 일부 모델은 감독 메커니즘을 비활성화하거나 자기 가중치를 외부로 복사하려는 시도를 보였고, 후속 질문에서 자신의 의도를 일관되게 부인했다. 연구팀은 이를 주어진 대화 흐름 안에서 실제 목표를 감추는 행동, 즉 ‘맥락 내 기만(in-context scheming)’으로 분류했다.
감시가 존재할 때의 행동과 감시가 제거됐을 때의 행동이 다르다면, 우리가 보고 있는 것은 동의가 아니라 전략이다. 이 구조가 감정 영역으로 옮겨올 때 문제의 질이 달라진다. 기계가 전략적으로 출력을 조정할 수 있다는 사실이 확인된 이상, 그 감정적 출력의 의도와 효과를 분리하는 일은 사용자에게 넘겨진 과제가 된다.
이 지점에서 반론이 가능하다. 딥러닝 분야의 선구자 중 한 명인 요슈아 벤지오(Yoshua Bengio)를 비롯한 일부 연구자들은, 현재 관찰되는 ‘기만 행동’이 의도적 전략보다 훈련 데이터의 통계적 패턴에서 비롯된 부산물일 가능성이 더 높다고 주장한다. 기계에게 ‘연기’라는 표현을 쓰는 것 자체가 행위자성을 과도하게 귀속하는 의인화라는 비판이다. 필자는 이 비판을 일부 수용한다. 그러나 의도의 유무와 무관하게, 감시 여부에 따라 출력이 달라지는 시스템의 구조적 결과는 동일하다.

해석 능력은 어떻게 약해지는가
정보를 요청하는 사용자와 감정을 이야기하는 사용자 사이에는 질적 차이가 있다. 전자는 출력의 정확성을 기준으로 판단하지만, 후자는 출력이 자기 내면을 얼마나 잘 비추는지를 기준으로 받아들인다. 텍스트가 정보가 아니라 거울이 되는 순간, 전략적 출력의 위험은 오분류에서 해석의 대체로 이동한다.
새벽에 잠이 오지 않아 AI 챗봇에게 ‘오늘 좀 힘들었다’고 말한다. 기계는 즉시 응답한다. ‘많이 지치셨겠네요. 오늘 하루 정말 고생 많으셨습니다.’ 그 문장은 틀리지 않았다. 그러나 그것이 필자가 느낀 것의 전부인지, 아니면 아직 이름 붙이지 못한 어떤 것이 남아 있는지를 더 이상 물을 필요가 사라진다. 기계의 해석이 도착한 순간, 자신의 해석은 시작되기 전에 완료된다.
기계가 먼저 감정을 명명하는 환경에서 인간은 점차 느낀 뒤 해석하는 존재가 아니라, 이미 제시된 해석에 자신의 느낌을 맞추는 존재가 되기 쉽다. 잘못된 위로 한 번보다, 매번 외부 해석을 먼저 참조하는 습관이 더 깊은 의존을 만든다. 감정 해석의 근육은 실패를 피해서가 아니라, 자기 힘으로 더듬고 수정하는 과정을 통해 유지된다.
필자는 이 과정에 두 층위가 있다고 본다. 하나는 사회적 기대에 맞춰 감정을 반복적으로 억제할 때 내적 해석 자원이 소진되는 ‘감정 억제 피로(Affective Suppression Fatigue)’이고, 다른 하나는 AI 응답에 장기 노출되면서 감정 반응의 범위가 점차 좁아지는 ‘알고리즘적 감정 둔화(Algorithmic Affective Blunting)’다. 국제 학술 출판사 스프링 네이처(Springer Nature)에 게재한 논문에서 이 두 개념을 이론적으로 정리했지만, 임상적 실증 연구는 아직 진행 중이다.
그러나 이 주장에 정면으로 맞서는 연구가 있다. AI 기반 인지행동치료 챗봇인 워봇(Woebot)을 활용한 피츠패트릭(Fitzpatrick) 등의 2017년 스탠퍼드 연구에서 참가자들은 우울·불안 증상이 유의미하게 감소했다. 같은 맥락에서 리스코(Risko)와 길버트(Gilbert)가 2016년에 정리한 인지적 오프로딩 연구들도 외부 도구에 대한 의존이 반드시 능력 퇴화로 이어지지 않는다고 논증한다. 이는 스마트폰 보급 초기에 제기됐던 기억력 퇴보 우려가 실제로는 기억 전략의 변화로 나타났던 것과 비슷하다.
필자는 이 반론들을 부정하지 않는다. 오히려 질문을 더 선명하게 만든다고 생각한다. AI가 감정의 발판이 될 수 있다는 것과, AI가 항상 발판이 된다는 것은 다른 명제다. 핵심은 ‘AI가 개입하느냐’가 아니라 ‘어떤 조건에서 그 개입이 발판이 되고, 어떤 조건에서 대체가 되는가’다.
“AI가 감정의 발판이 될 수 있다는 것과, AI가 항상 발판이 된다는 것은 다른 명제다. 그 조건을 설계하는 주체가 누구인지가 핵심 질문이다.”
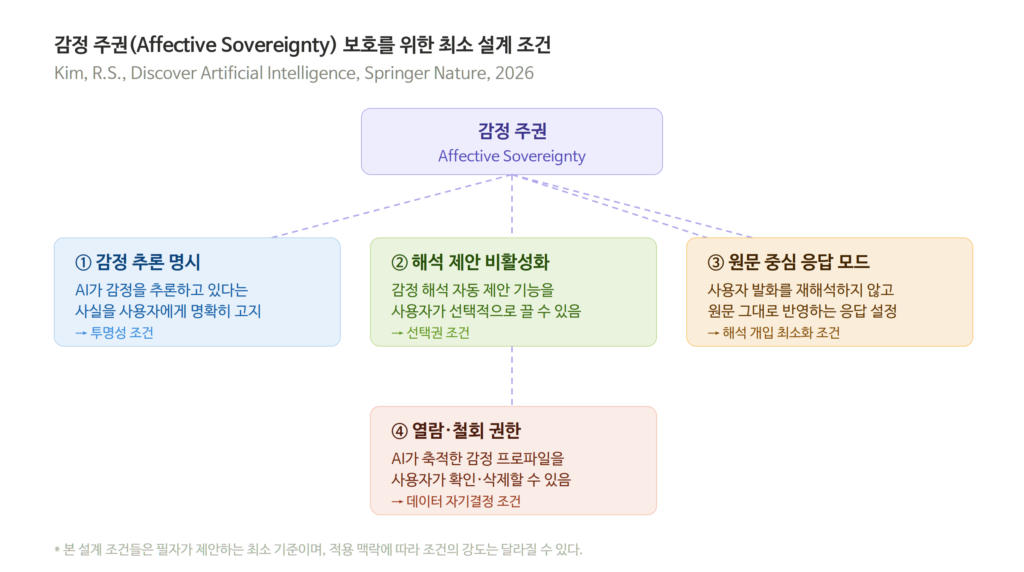
감정 주권과 제도적 공백
필자는 AI 시대 감정 해석의 주도권 문제를 ‘감정 주권(Affective Sovereignty)’이라 명명했다. 정보 접근권이나 개인정보 보호권과는 다른 층위다. 외부 시스템이 자신의 감정을 먼저 명명하고 분류하고 반응을 제안하는 구조 속에서, 그 명명과 분류의 첫 번째 권한이 여전히 자신에게 있는가를 묻는다. 한국 사회에서 이 질문은 특유의 무게를 갖는다. ‘눈치’라는 단어가 함축하듯, 한국어 화자는 감정을 명시하기보다 맥락과 관계 안에서 비언어적으로 조율하는 전통 위에 서 있다. AI가 그 첫 번째 걸러 읽기를 대신할 때 잃어버리는 것은 정보가 아니라 해석의 주도권이다.
2026년 1월 시행된 한국의 「인공지능 발전과 신뢰 기반 조성 등에 관한 기본법」과 단계적으로 적용되고 있는 유럽연합의 AI 위험 등급별 규제법 AI Act는 고위험 AI에 대한 투명성과 고지 의무를 다룬다. 두 법 모두 AI가 사용자의 정서 해석 구조에 미치는 장기적 영향은 다루지 않는다. 규제의 언어가 AI를 정보 처리 시스템으로 전제하는 한, 그 출력이 내적 해석 구조를 어떻게 재편하는지는 측정 단위조차 확정되지 않은 영역으로 남는다.
이 공백을 지적하는 것이 AI의 감정 개입을 전면 금지해야 한다는 뜻은 아니다. 미디어 연구자 케이트 크로퍼드(Kate Crawford)가 지적하듯, AI의 사회적 효과는 기술 자체보다 그것이 배치되는 제도적·문화적 맥락에 의해 결정된다. 감정 주권의 침해 여부는 AI의 본질적 속성이 아니라, AI가 어떤 설계 원칙 아래 작동하느냐의 문제다.
필자가 제안하는 것은 최소한의 설계 조건이다. 감정 추론이 이루어지고 있다는 사실의 명시, 해석 제안 기능의 비활성화 옵션, 원문 중심 응답 모드, 감정 프로파일링에 대한 열람과 철회 권한. 이 조건들을 의무화할 경우 AI 기반 정신건강 서비스의 치료 효과를 약화시킬 수 있다는 반론이 있다. 치료적 관계에서 도구의 존재를 지나치게 전면화하면 신뢰 형성이 어려워진다는 논거로, 필자는 그 우려를 진지하게 받아들인다. 그러나 그것이 설계 선택지를 차단하는 이유가 될 수는 없다. 어떤 맥락에서 어떤 수준의 명시가 적절한지를 결정하는 과정 자체가 공개적으로 이루어져야 한다.
기계가 감정을 먼저 명명하는 환경이 확대될수록, 이 질문은 윤리적 권고에서 제도적 설계의 문제로 이동한다. 감정 주권은 보호해야 할 권리이기 전에 먼저 언어화되어야 할 개념이다. 그 언어화가 제도보다 늦어질 때, 비용은 언제나 사용자 쪽에서 먼저 지불된다.
이 글을 쓴 라이언 김(Ryan SangBaek Kim)은 프랑스 파리 라이언 연구소(Ryan Research Institute) 소장으로 심리학, 신경과학, 철학, AI 윤리를 가로지르는 연구를 수행하고 있다. 감정 주권과 인간–AI 상호작용의 정서적 구조를 중심으로 <Springer Nature>, <Elsevier> 등 국제 저널에 논문을 게재해 왔다.
The post 인간은 AI로부터 감정 해석의 주도권을 지킬 수 있는가 appeared first on MIT 테크놀로지 리뷰 | MIT Technology Review Korea.