2026년 반도체 대분기, ‘공정’ 아닌 ‘공급’이 한국 반도체 가른다
2026년 반도체 대분기는 기술 경쟁 이후의 단계에 들어섰다. 이제 한국 반도체의 승부는 공정이 아니라 공급에서 갈린다. 공정 격차는 좁혀질 수 있지만, 공급 구조에서 밀리면 다음 물량 배정에서 제외될 수 있다.
AI 산업의 무게중심이 바뀌었다. 더 크고 빠른 모델을 훈련하기 위해 수백억 달러의 자본과 기가와트급 전력을 클러스터에 쏟아붓던 확장 경쟁은 이미 정점을 통과했다. 지금 산업의 실질적인 승부는 학습이 완료된 모델을 실제 서비스 환경에서 매 순간 안정적으로 호출하고 지속 운용할 수 있는가, 즉 추론(inference)의 효율과 회복력을 누가 먼저, 그리고 더 깊이 확보하느냐의 문제로 이동하고 있다.
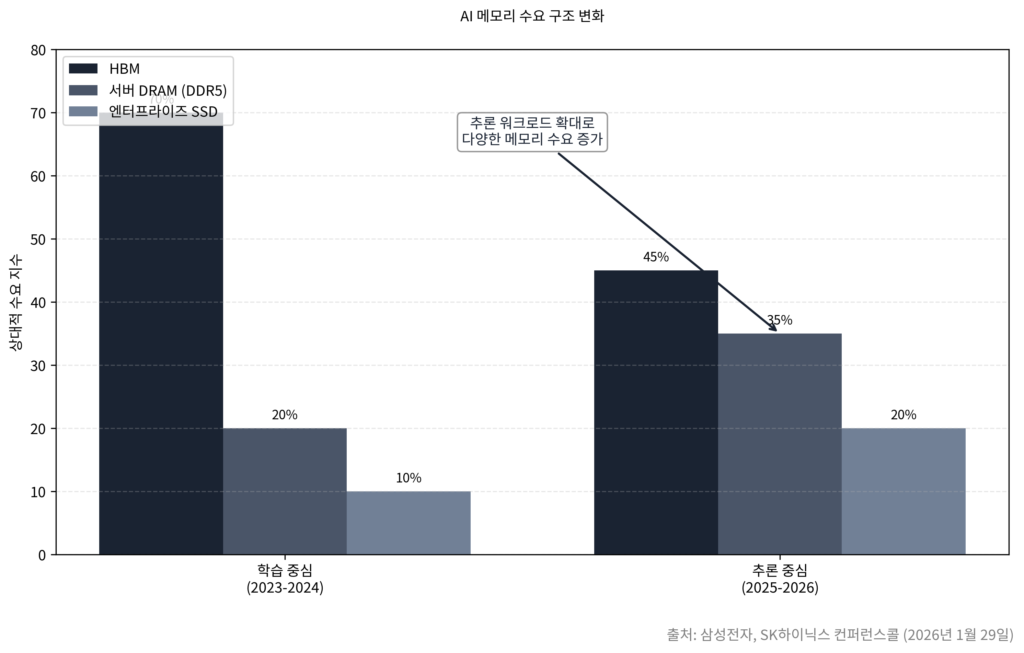
이 전환은 반도체 수요 구조에서 이미 수치로 나타나고 있다. 올해 1월 말 각각 진행된 컨퍼런스콜에서 삼성전자와 SK하이닉스는 고대역폭 메모리(HBM)를 넘어 서버용 고용량 D램과 기업용 SSD 수요가 동시에 빠르게 확대되고 있다고 밝혔다. 추론 서비스는 모델이 사용자 요청을 받을 때마다 메모리와 스토리지를 반복적으로 소비하는 구조를 만든다. 누적되고 예측 가능하며 장기적인 이 소비 패턴이 반도체 수요의 중심으로 부상하면서, 두 회사는 공정·패키징·공급 전략을 추론 워크로드 중심으로 재배치하고 있다고 설명했다.
공정·패키징·수율 분석 분야 최고회 기술 펠로우인 테크인사이트의 최정동 수석부사장은 MIT 테크놀로지 리뷰 코리아와의 인터뷰에서 이 변화가 고객의 선택 기준 자체를 바꾸고 있다고 말했다. 최 수석부사장은 “전력 대비 성능과 대역폭은 중요하지만, 그보다 수율 안정성, 로드맵 신뢰성, 공급망의 회복력이 우선적”이라며 “향후 HBM4와 그 이후 세대의 결정적 요인은 대규모 생산에서의 신뢰성”이라고 강조했다.

HBM4 퀄 테스트 통과의 진짜 의미
HBM2에서 HBM3까지의 경쟁은 비교적 명확했다. 대역폭, 적층 수, 전력 효율 같은 수치로 비교 가능한 성능 지표를 누가 먼저 구현하느냐의 싸움이었다. 그러나 AI 수요의 무게중심이 학습에서 추론으로 이동하면서 메모리 시장의 문법은 빠르게 달라지고 있다.
추론 중심의 AI 서비스는 GPU 옆에 붙는 HBM만으로는 작동하지 않는다. 수천 개의 쿼리를 병렬로 처리하는 데이터센터에서 시스템 전체를 떠받치는 것은 결국 대량의 범용 서버 D램이다. 문제는 두 시장의 격차다. HBM 생산량을 늘리기 위해 삼성전자와 SK하이닉스가 기존 D램 설비를 HBM 전용 라인으로 전환하면서, 범용 DDR5 공급은 오히려 빠듯해졌다. 수요는 급증하는데 공급은 줄어드는 구조가 만들어졌다.
글로벌 IT·반도체 시장조사업체 카운터포인트 리서치는 2026년 1분기 일부 범용 D램 제품군의 수익성이 HBM을 상회하는 비정상적인 구간이 나타났다고 분석했다. 이어 일부 제품군의 메모리 가격이 전 분기 대비 최대 80~90% 급등했다고 밝혔다. 미국 메모리 반도체 기업 마이크론(Micron)의 산제이 메로트라 (Sanjay Mehrotra) CEO는 2026년 1월 컨퍼런스콜에서 “HBM을 포함한 모든 D램 영역에서 수요와 공급의 격차가 역사상 최고 수준에 도달했다. 2026년 물량은 이미 대부분 예약이 끝났다”고 전했다.
이런 상황에서 삼성전자가 HBM4의 양산 출하를 공식화한 것은 분명한 전환점이다. 퀄리피케이션 테스트(이하, 퀄 테스트)는 단순한 성능 검증이 아니다. 특정 메모리가 고객의 시스템 설계와 양산 일정에 실제로 편입될 수 있는지를 확인하는 절차다. 이번 출하로 삼성전자의 HBM4는 엔비디아 차세대 GPU 플랫폼 ‘베라 루빈(Vera Rubin)’을 포함한 주요 AI 가속기 로드맵의 공급 후보군에 포함됐다. 업계에서는 일정 압박 속에 엔비디아가 최종 검증 이전에 선제적 물량 확보를 요청했을 가능성을 거론하고 있다.
트렌드포스 반도체 전문 톰 슈(Tom Hsu) 분석가는 MIT 테크놀로지 리뷰 코리아와의 인터뷰에서 “삼성전자가 HBM4 퀄리피케이션(품질인증) 및 제품 성능 면에서 경쟁사들을 빠르게 추적하고 있다고 보고 있다”면서 “이는 엔비디아가 2025년 3분기 HBM4의 I/O(입출력) 속도 요구 사항을 상향 조정한 이후 더 명확해졌다”고 말했다.
최 수석부사장은 삼성전자의 HBM4 양산 출하에 대해 “기본적인 속도와 단기 테스트 등 주요 항목을 통과했기 때문에, 차세대 제품 로드맵을 고려해 선제적으로 물량을 요청한 것으로 보인다”며 “엔비디아 입장에서는 속도뿐 아니라 대역폭, 수율, 공급 안정성, 장기적 열 안정성까지 종합적으로 판단하며, 물량이 급증하는 상황에서는 공급망 리스크를 최소화하는 것이 중요한 의사결정 요소”라고 설명했다.
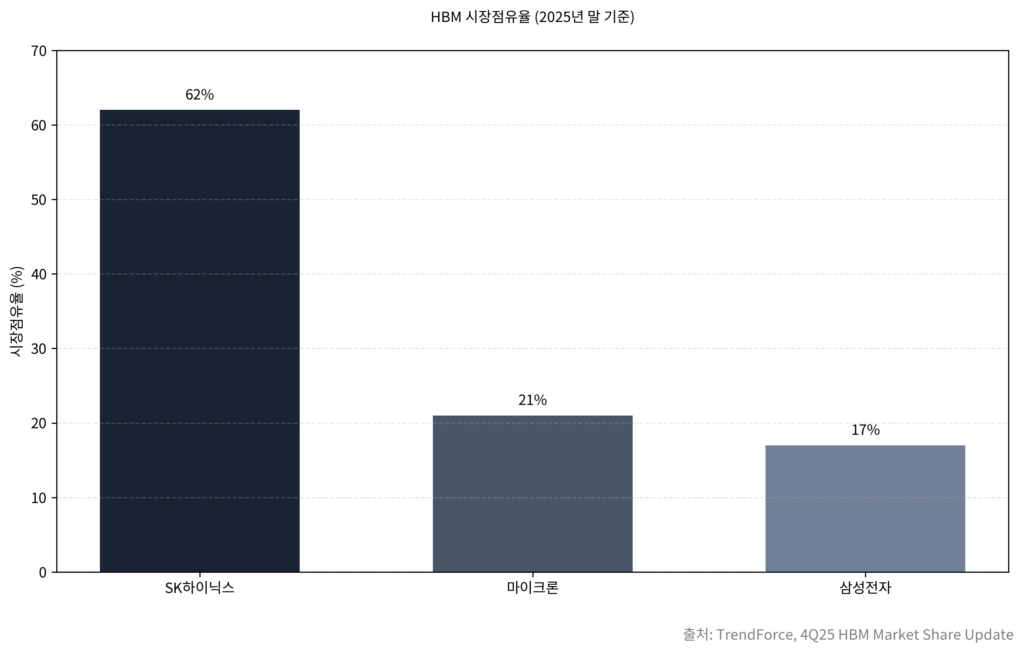
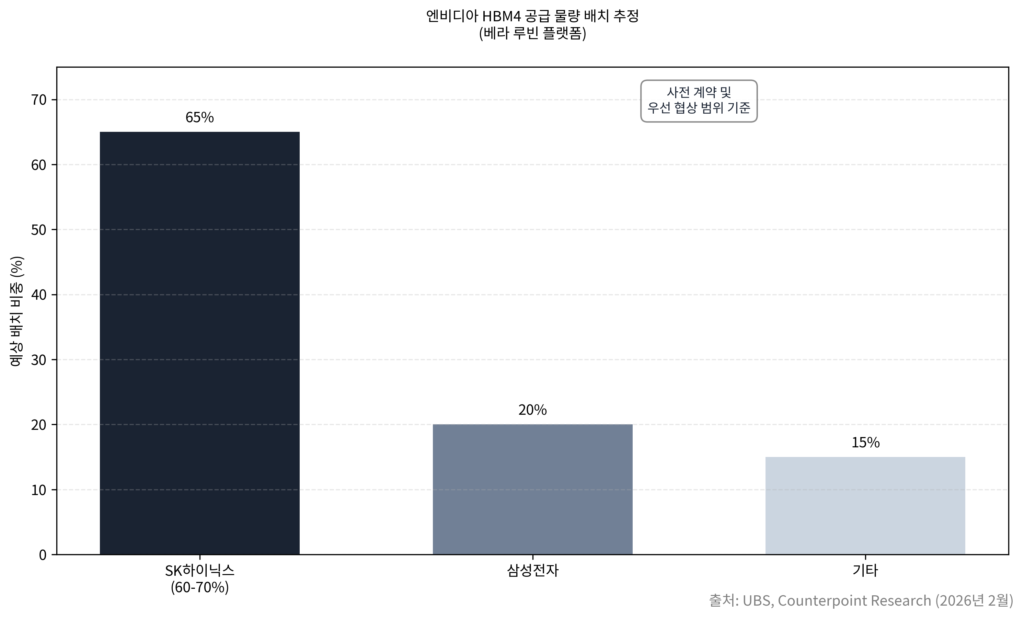
반면 SK하이닉스는 2025년 하반기부터 주요 고객을 대상으로 HBM4 엔지니어링 샘플을 공급하며 단계별 퀄리피케이션을 진행해왔다. 트렌드포스와 카운터포인트 리서치는 SK하이닉스가 엔비디아의 차세대 HBM4 물량 가운데 약 60~70%를 사전 계약 또는 우선 협상 범위로 확보한 것으로 추정한다. UBS 글로벌 리서치도 “SK하이닉스가 루빈 플랫폼에 탑재될 HBM4 시장의 약 70%를 선점할 것”이라고 전망했다. 트렌드포스는 2025년 말 기준 HBM 시장에서 SK하이닉스가 약 62%의 점유율로 1위를 굳혔고, 삼성전자는 약 17%, 마이크론은 약 21% 수준이라고 추정했다.
최 수석부사장은 퀄 테스트가 “시작 조건에 가깝다”고 표현했다. 인터뷰에서 그는 “고객들은 퀄 테스트 이후에도 양산 수율의 변동폭과 일정 예측 가능성을 가장 중요하게 본다. 로드맵 단위에서 신뢰가 유지될 수 있는지가 실제 선택을 좌우한다”고 말했다.
트렌드포스 반도체 부문 수석부사장 에이브릴 우 역시 MIT 테크놀로지 리뷰 코리아와의 인터뷰에서 “HBM 경쟁의 최대 병목은 ‘칩 통합’”이라며 “HBM4 이후 세대에서는 단순히 대역폭을 높이는 것이 아니라, 메모리 내부에 더 많은 제어 기능이 통합되는 방향으로 구조가 바뀌고 있다”고 설명했다.

결정권은 누구에게 있는가,
HBM4 배치는 ‘기술’이 아니라 ‘구조’가 정한다
2026년 HBM4 경쟁에서 물량 배치의 결정권은 메모리 업체에 있지 않다. 설계는 엔비디아와 AMD가 시작한다. GPU 아키텍처와 인터페이스, 전력 조건을 먼저 확정하고 그 설계를 실제로 받아낼 수 있는지를 묻는다. 그 답은 TSMC의 공정과 패키징 병목에서 갈린다. 어느 공정이 언제 열리고, 어느 패키징 라인이 실제로 비어 있는지가 곧 물량 배치의 상한선을 정한다.
이 구조의 핵심은 HBM의 ‘베이스 다이(Base Die)’다. HBM4에 이르러 대역폭과 적층 수가 늘어나면서 신호 제어와 전력 관리가 복잡해졌고, 이를 기존 메모리 공정으로는 감당하기 어려워졌다. 그 결과 베이스 다이는 파운드리의 로직 공정에서 제조되기 시작했고, 메모리 컨트롤러, 오류 정정(ECC), 전력 관리 기능을 직접 수행하는 ‘작은 시스템 반도체’에 가까운 성격을 띠게 됐다. HBM4부터 메모리는 필요할 때 조달해 쓰는 범용 부품의 개념을 벗어난다. GPU 설계 시작부터 어느 공정에서 만들고 어느 패키징 라인을 통과할지가 함께 정해지기 때문이다.
트렌드포스 우 수석부사장은 “HBM 베이스 다이가 더 진보된 로직 노드로 이동하면서 설계 복잡성과 수율 제어의 진입 장벽이 크게 높아지고 있다”면서 “동시에 파운드리 파트너와의 협력이 갈수록 중요해질 것이다. 만약 품질 인증 일정에 차질이 생기면 전체 HBM 양산 일정이 함께 밀릴 수밖에 없다”고 덧붙였다.
시장 보도에 따르면 초기 16단 HBM4 양산 구간에서 삼성전자의 수율이 SK하이닉스보다 상대적으로 낮다는 추정이 제기됐다. 삼성전자는 일부 매체에서 약 50~60% 수준으로 거론되는 반면, SK하이닉스는 80~90% 수준의 수율을 확보한 것으로 보도되기도 했다. 다만 이 수치는 양사 공식 발표가 아닌 시장 추정치로 해석해야 한다. 최 수석부사장은 이에 대해 “시장에서는 이를 기술 격차라기보다 고객이 어느 쪽 물량을 실제 설계에 얹을 수 있는지를 판단하는 근거로 작동한다. HBM의 경쟁력은 샘플 성능이 아니라, 고객이 실제로 물량을 어디에 배치했느냐를 보면 드러난다”고 설명했다. 메모리 업체의 전략은 결국 이 병목 구조 안에서 ‘얼마나 안정적으로 편입될 수 있는가’의 문제로 수렴한다.
2026년 반도체 패권은 ‘패키징’에서 갈린다
패키징은 흔히 완성된 칩을 ‘싸는 기술’로 오해되지만, AI 시대의 패키징은 칩이 설계대로 작동하도록 마지막 조건을 맞추는 단계에 가깝다. 연산 성능과 전력 특성, 열 분산과 신호 무결성이 이 단계에서 동시에 검증된다.
최 수석부사장은 HBM4 이후의 패키징을 두고 “칩을 만드는 공정과, 그 칩들을 묶는 패키징을 따로 최적화해서는 안정적인 수율을 기대하기 어렵다”고 설명한다. 예전에는 패키징이 완성된 칩을 물리적으로 연결하는 마지막 단계에 가까웠다면, 이제는 역할이 달라졌다는 것이다.
HBM4부터는 메모리 아래쪽에 위치한 ‘베이스 다이’가 단순한 연결 부품이 아니라, 데이터 흐름과 전력을 제어하는 역할까지 맡기 시작했다. 이 때문에 메모리 공정에서 만든 칩과, 파운드리에서 만든 로직 칩이 함께 작동해야 한다. 패키징은 단순히 칩을 붙이는 작업이 아니라, 서로 다른 공정에서 나온 칩들이 충돌 없이 하나의 시스템처럼 움직이도록 조정하는 과정으로 바뀌고 있다. 이 시점에서 패키징은 ‘포장’이 아니라 ‘조율’에 가까운 단계가 된다. 우 수석부사장도 차세대 HBM이 단순히 데이터 전송 속도를 높이는 방향이 아니라, 메모리 안에서 더 많은 제어 기능을 직접 처리하는 구조로 바뀌고 있다고 설명한다.
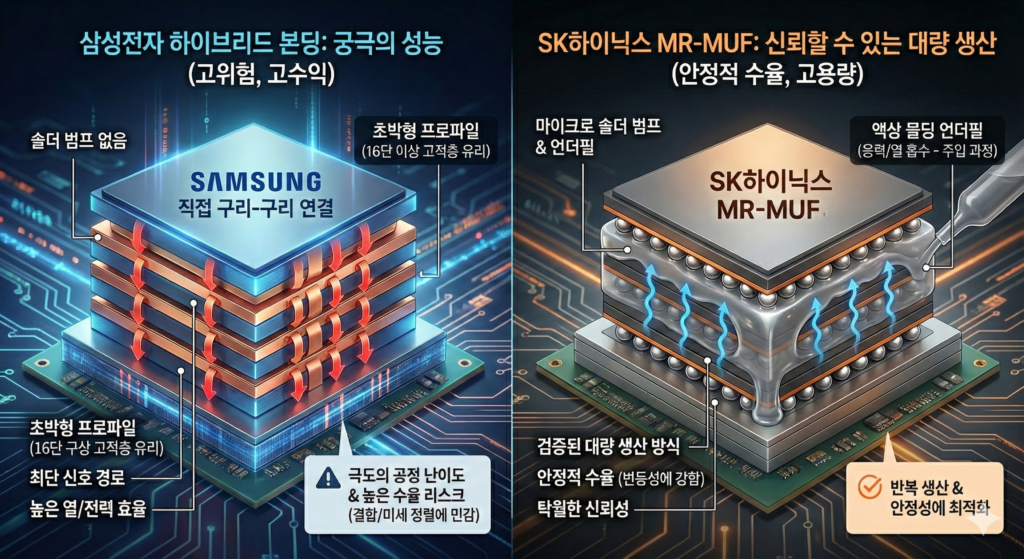
이 지점에서 한국의 두 메모리 기업의 선택은 분명히 갈린다. SK하이닉스는 이미 안정화된 공정을 기반으로 HBM4 초기 물량을 준비하고, 고단 적층에서도 열과 구조적 안정성을 확보하기 위해 MR-MUF 패키징 기술을 고도화했다. HBM4의 핵심 부품인 베이스 다이는 TSMC의 로직 공정에서 제조하고, 이를 CoWoS(Chip-on-Wafer-on-Substrate) 패키징 생태계 안에서 통합하는 전략을 택했다. 이는 GPU 설계부터 패키징까지 이미 검증된 경로를 활용하는 방식으로, 고객 입장에서는 일정과 품질 측면에서 변수가 가장 적다.
삼성전자는 다른 길을 택했다. 메모리와 파운드리, 패키징을 한 회사 안에서 모두 처리하는 턴키 전략을 유지하고 있다. 자체 파운드리에서 HBM4용 로직 다이를 생산하고, 칩 간 접합 밀도를 높이는 하이브리드 본딩 패키징 기술을 적용해 고단 적층의 한계를 넘겠다는 구상이다. 고객별 요구에 맞춰 설계부터 양산까지를 통합해 최적화하겠다는 접근이다.
다만 이 전략은 기술적 완성도와 별개로 공급 구조가 특정 벤더에 묶일 수 있는 ‘벤더 락인(Vendor lock-in)’ 리스크로 인식될 수 있다. 실제로 빅테크 같은 하이퍼스케일러들은 패키징을 기술 경쟁이 아니라, 문제가 발생했을 때 대체 경로가 존재하는지 여부, 즉 공급 안정성과 일정 리스크의 문제로 판단하고 있다. 이 같은 흐름은 시장 전망에서도 확인된다. 골드만삭스는 2026년 1월 보고서에서, AI 반도체 시장이 단순한 성능 경쟁을 넘어 커스텀 ASIC(특정 목적에 맞게 설계된 맞춤형 반도체)과 이에 결합되는 메모리·패키징 구조 중심으로 재편되고 있다고 분석했다. 이 과정에서 메모리 업체는 부품 공급자를 넘어, 설계 단계부터 책임 범위를 함께 떠안는 파트너로 이동하고 있다는 평가다.
우 수석부사장은 “구글이나 메타 같은 빅테크 기업들로 인해 메모리 시장 구조는 ‘구매자-판매자’ 관계에서 더 깊은 단계의 ‘공동 개발(Co-development)’ 모델로 점점 변화할 것이다”라고 말했다. 이어 그는 “이러한 커스텀 HBM은 엔비디아에 대한 의존도를 낮추기 위한 목적이 크지만, HBM과 고용량 DDR5 메모리는 여전히 AI 시스템 성능을 결정짓는 핵심 병목 지점이며, 메모리 공급업체들은 최소한 2027년까지 상대적으로 강력한 협상력과 가격 결정권을 유지할 것으로 보인다”고 설명했다.
미래 전망: 메모리는 시스템이 된다
HBM4 이후 버퍼리스 HBM, HBF(High Bandwidth Flash), CXL(Compute Express Link)이 함께 거론되는 이유는 분명하다. 세 기술은 공통적으로 더 빠른 메모리를 만드는 것이 아니라, 시스템 전체의 동작 방식과 안정성을 개선하는 데 초점을 두고 있다.
버퍼리스 HBM은 이 변화를 가장 직접적으로 보여준다. 기존 HBM에서는 데이터 신호를 안정시키는 완충 장치인 ‘버퍼’가 메모리 안에 들어 있었다. 그러나 버퍼리스 HBM에서는 이 완충 장치가 사라지고, 그 역할을 연산 칩과 메모리를 연결하는 설계·패키징 단계에서부터 직접 맞춘다. 최 수석부사장은 “성능을 얼마나 더 낼 수 있느냐보다, 어디서 오류를 잡고 어디서 끊어낼 수 있느냐가 더 중요해진다. 어디서 끊을 수 있는지 설계 단계에서 정의돼 있지 않으면 운영 리스크가 급격히 커진다”고 강조했다.
HBF는 낸드 플래시를 수직으로 적층해 D램보다 훨씬 큰 용량을 AI 시스템 가까이에 배치한다. 낸드 플래시는 전원이 꺼져도 데이터가 유지되는 비휘발성 메모리로, 대용량을 상대적으로 낮은 비용으로 구현할 수 있다. 아직 상용화 단계는 아니지만, HBM을 대체하기보다 HBM의 용량 한계를 보완하는 계층으로 논의되고 있다.
CXL은 이 변화를 서버 내부를 넘어 데이터센터 전체로 확장한다. CXL 3.0 이후 메모리는 한 서버에 고정된 부품이 아니라 필요에 따라 옮기고 나눠 쓰는 공유 자원처럼 다뤄진다. 마치 저장 공간을 여러 컴퓨터가 함께 쓰는 것과 비슷한 구조다. 이 환경에서는 속도를 조금 더 높이는 것보다 문제가 생겼을 때 빠르게 감지하고 해당 영역만 분리해 나머지 시스템을 계속 돌릴 수 있는 설계가 훨씬 중요해진다.
이러한 반도체 전망은 기술 경쟁의 다음 단계를 보여준다. HBM4 이후의 경쟁은 더 이상 숫자로 비교되는 성능의 문제가 아니다. 설계와 공정, 패키징, 나아가 데이터센터 운영까지 하나의 흐름으로 연결되는 구조 속에서 각 기업은 어디까지 책임지고 어떤 역할을 맡을 것인지 선택해야 한다. 2026년 반도체 대분기의 승부는 누가 더 빠른 칩을 만들었는지가 아니라, 누가 더 안정적인 시스템을 만들고 그 구조를 끝까지 감당할 수 있는지에 달렸다.
The post 2026년 반도체 대분기, ‘공정’ 아닌 ‘공급’이 한국 반도체 가른다 appeared first on MIT 테크놀로지 리뷰 | MIT Technology Review Korea.